はじめに
こんにちは。トランジェンのHです。ここではトランジェンが持つ技術的な情報を掲載します。今回は、前回の続きです。まだ読んでいない方前回の記事をお読みください。使用するTradosのバージョンは2011です。
対処方その1 HTMLにする
前回、「テキスト置換によるペナルティ」を99%で指定することによってタグの順番の問題の解決策としましたが、現実的であるとは言えません。
そこで前回より現実的な対処方を考えました。
まず、実は重要なことをお伝えしていませんでしたが、タグの順番が入れ替わるのは「南京錠アイコン」がつくときだけ、です。Trados2011で南京錠アイコンが付くのはXMLだけ。つまり、XMLで「翻訳対象外」に設定したタグだけが前回の問題を引き起こします。
では南京錠アイコンがつかないようにすれば、この問題は回避できます。つまりXMLではなくHTMLにすることで回避できるのです。ちなみに2014ですとHTML5は南京錠アイコンが付きます。

100%で次の訳が入っています。
この方法の問題点はHTMLにしなければならないことです。すでにXML形式で翻訳を進めていた場合は翻訳ファイルから作り直さなくてはならず手間がかかります。とはいえ一番確実でお手軽な方法でしょう。
対処方その2 属性の値に文章を入れる
南京錠アイコンが出ないようにする・タグに囲まれた文章は翻訳して欲しくない、この二つの希望を同時に叶えるのがタグの属性に翻訳対象を入れる方法です。少々変則的な方法です。
サンプルの文章を次のようにします。
Install <strong="AAA" /> that is pre-installed in your <strong="BBB" /> memory.
strongタグのs属性の値に翻訳対象外としたい文章を入れます。Tradosで翻訳すると次のようになります。
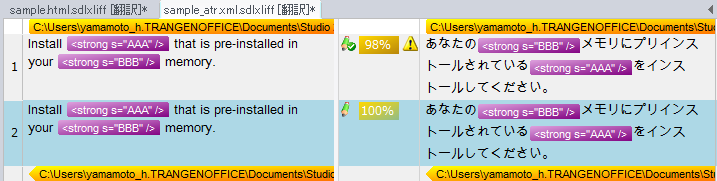
HTMLにしたときと同じようになりました。
この方法の欠点は結構あります。
- タグの属性の値として指定できない文章は使えない
- 常にタグを属性まで表示しないと保護された文章が読めないため、翻訳の際にタグが邪魔に感じる
- 翻訳ファイルの前処理(属性の値に指定する)をしなくてはならない
- 翻訳後のファイルに対して属性から外す後処理が必須になる
しかし変則的ですがXMLでタグ内の文章を保護したいのならこれしかありません。
原因について
南京錠アイコンを使用しないようにすれば回避できることが分かりました。つまり南京錠アイコンが表示されるときの翻訳メモリーの仕組みに鍵が隠されていると判断できます。
XML(南京錠アイコン)の翻訳メモリー

上図は翻訳メモリーをSDL Trados Studioアプリケーションから見たところです。南京錠アイコンに囲まれてBBB・AAAと表示されています。
この翻訳メモリーをエクスポートします。形式はtmx1.4bとなっています。tmxとは「Translation Memory eXchange」の略で、翻訳メモリーの標準規格です。エクスポートしたtmxファイルをテキストエディタで開きます。tmxはXMLベースの規格なのでそのまま開けます。
<tuv xml:lang="en-US"> <seg>Install <bpt i="1" type="x-LockedContent" x="1" />AAA<ept i="1" /> that is pre-installed in your <bpt i="2" type="x-LockedContent" x="2" />BBB<ept i="2" /> memory.</seg> </tuv> <tuv xml:lang="ja-JP"> <seg>あなたの<bpt i="1" type="x-LockedContent" x="1" />BBB<ept i="1" />メモリにプリインストールされている<bpt i="2" type="x-LockedContent" x="2" />AAA<ept i="2" />をインストールしてください。</seg> </tuv
原文と訳文の対訳部分を抜き出しました。南京錠アイコンの部分はbptタグとeptタグで表されています。ここのx属性に注目してください。数字が書かれています。これが実は今回の問題の原因です。
HTML版の翻訳メモリー

XMLの場合と違ってタグの部分がただの数字になっています。ではXMLと同じようにエクスポートしましょう。
<tuv xml:lang="en-US"> <seg>Install <ph x="1" type="2" /> that is pre-installed in your <ph x="2" type="3" /> memory.</seg> </tuv> <tuv xml:lang="ja-JP"> <seg>あなたの<ph x="2" type="3" />メモリにプリインストールされている<ph x="1" type="2" />をインストールしてください。</seg> </tuv>
XMLではタグがbpt・eptでしたが、HTMLではphだけです。x属性を見てみましょう。原文(英語)ではそれぞれ「x=”1″, x=”2″」です。
日本語ではこれが「x=”2″, x=”1″」と逆になっています。上図を見ても2・3とタグの部分がID化されていますが、原文と訳文で順番が違います。
翻訳メモリーではx属性の値によって、タグをID化しています。訳文でタグの順番が異なる場合は、異なった順番の通りにIDを振り分けています。
結論
HTMLではx属性の値、つまりタグのID化が働いていましたが、XMLではx属性が翻訳単位ごとのタグの出現順番に番号が振られているだけでタグのID化が機能していません。そのため、前回のようにタグを入れ替えても「タグが入れ替わった」ということがTradosは分からなかったというわけです。
では2014はx属性のタグのID化が働くようになったのか? というと実はそうではありせん。2014では翻訳対象外の文章、サンプルでは「AAA・BBB」をIDの代わりに参照しています。なので、当然ですが「AAA・BBB」以外の文字を使用すれば順番は入れ替わりません。その場合新たに「AAA・BBB」以外の文字を使用した翻訳単位を翻訳メモリーに登録する必要があります。
しかし2014で順番が入れ分からない条件は「タグ以外の文章が全て同一でタグのみ異なる場合」だけです。なぜならタグ以外の文章が異なれば、異なる翻訳単位として翻訳メモリーに登録されるからです。異なる翻訳単位なら、翻訳メモリーから呼び出す時、そもそも一致しないので呼び出されないのですから。
ちなみにTrados2007でなぜこの問題が起きないのか、というと2007ではタグと保護した文章どちらも参照しているからです。
これはTradosが扱うTMXの仕様の問題でして2007ではTMXではなく別の方法で翻訳メモリーを管理していたのです。
如何だったでしょうか。これでタグの問題に関する記事は終了です。Tradosにはいろいろと奇妙な仕様があります。この記事が読者に役立つ記事となることを祈ります。
このTradosのタグの扱いの感想をお待ちしております。また、実際の翻訳処理の中でご相談がある場合はお気軽にお問い合わせください。
いろいろ勉強になりました^o^!
コメントありがとうございます。参考になれば幸いです。
これからもTradosについていろいろ書いていく予定ですので、何か記事にして欲しいことがお知らせください。